在移动设备和嵌入式系统中,Mali GPU凭借其优异的能效比,已成为图形渲染与通用计算的关键组件。将计算密集型的二维浮点矩阵运算(如矩阵乘法、卷积等)迁移至Mali GPU执行,能显著提升性能并降低CPU负载。本文将深入探讨Mali GPU的编程特性,并结合实战技巧,详细解析针对二维浮点矩阵运算的并行优化策略。
一、Mali GPU核心架构与编程模型特性
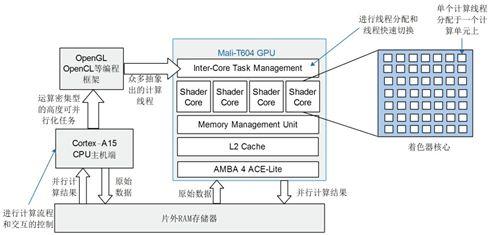
Mali GPU通常采用基于瓦片(Tile-Based)的渲染架构,其计算核心由着色器核心(Shader Core)组成。在编程层面,主要支持OpenCL ES(用于通用计算)和Vulkan(兼顾图形与计算)两种API。关键特性包括:
- 分层内存体系:包括私有内存(Private Memory,线程独享)、本地内存(Local Memory,工作组内共享)和全局内存(Global Memory,所有线程可见)。优化数据在各级内存间的移动是性能关键。
- SIMD/SIMT执行模型:Mali GPU通过单指令多线程(SIMT)方式执行,一个线程束(通常是4个线程)同步执行相同指令但处理不同数据。
- 工作组(Work-Group)调度:计算任务被划分为工作组,在着色器核心上调度执行。合理的工作组大小对隐藏访存延迟至关重要。
二、二维浮点矩阵运算的并行化分解策略
以矩阵乘法C = A × B(假设维度均为N×N)为例,经典的优化思路是:
- 线程映射:将输出矩阵C的每个元素(或一个小块)的计算分配给一个独立的GPU线程。这样可生成N×N个并行任务,实现大规模并行。
- 工作组划分:将输出矩阵划分为若干二维块(如16×16或32×32),每个块由一个工作组负责计算。工作组内线程通过本地内存协作,高效复用从全局内存读取的A和B矩阵数据块。
- 循环分块(Tiling)优化:由于单个元素计算需要访问A的一整行和B的一整列,直接实现会导致大量重复的全局内存访问。优化方法是:将计算分解为多个阶段,在每个阶段,工作组先将A的一个子块和B的一个子块从全局内存加载到快速的本地内存中,然后所有线程基于这些子块进行部分和累加。这能极大减少昂贵的全局内存访问次数。
三、针对Mali GPU的关键优化技巧
- 优化内存访问模式:
- 合并访问(Coalesced Access):确保工作组内连续的线程访问全局内存中连续(或具有规则步长)的地址。例如,在读取矩阵A的块时,让线程0读取A(0,0),线程1读取A(1,0)... 这样多次访问可被合并为一次更宽的内存事务,大幅提升带宽利用率。
- 充分利用本地内存:将频繁访问的共享数据(如矩阵的特定行/列块)载入本地内存。Mali GPU的本地内存延迟远低于全局内存,是性能提升的核心。
- 向量化数据类型:使用
float4、float8等向量类型进行加载、存储和计算。这能更有效地利用内存带宽和ALU单元。
- 调整工作组配置:
- 工作组大小:通常设置为二维,如(16, 16)或(8, 8),并使其总大小(256或64)是GPU硬件线程束大小的整数倍,且符合OpenCL ES的设备限制。这有助于提高计算资源的占用率。
- 工作项(Work-Item)分工:除了为每个输出元素分配一个线程的基本模式,还可以让一个线程负责计算一个小型矩阵块(如2×2),以减少线程创建开销并增加指令级并行。
- 指令级优化与注意事项:
- 减少寄存器压力:Mali GPU每个着色器核心的寄存器数量有限。应避免在内核中使用过多私有变量,或通过循环展开时谨慎控制展开因子,以防寄存器溢出导致性能下降。
- 平衡计算与访存:通过增加每个线程的计算量(如计算更大的输出块)来分摊固定的内存访问开销,提升计算访存比。
- 精度选择:根据需求,可考虑使用
mediump(中等精度)浮点数进行计算,这在Mali GPU上通常更快且功耗更低,但需评估精度损失是否可接受。
四、实战优化流程与性能评估
- 基线实现:首先实现一个简单的、每个线程计算一个输出元素的核函数,作为性能基准。
- 引入循环分块与本地内存:实现利用本地内存缓存数据块的版本,观察性能提升。
- 优化内存访问模式:调整线程的数据读取顺序,确保合并访问;尝试使用向量化加载。
- 微调参数:系统性地调整工作组大小、循环分块大小、每个线程负责的输出区域大小等参数,找到针对特定Mali型号和矩阵尺寸的最优组合。
- 性能分析工具:利用Arm Mobile Studio中的Streamline或Mali Offline Compiler等工具,分析内核的硬件计数器(如缓存命中率、ALU利用率、内存带宽),定位瓶颈。
在Mali GPU上优化二维浮点矩阵运算,精髓在于最大化数据复用、最小化全局内存访问、以及保持硬件执行单元的高占用率。通过深刻理解其瓦片式架构和内存层次,并灵活运用循环分块、向量化、工作组优化等技巧,开发者能够充分释放Mali GPU的并行计算潜力,为移动端AI推理、图像处理等应用带来显著的性能加速。