在人工智能的浪潮中,边缘计算正日益成为推动AI应用落地的关键力量。百度推出的EdgeBoard边缘AI计算盒,作为专为边缘场景设计的硬件平台,其核心驱动力在于对卷积神经网络(CNN)的高效、低功耗部署。本文旨在剖析EdgeBoard中CNN架构的实现,并深入探讨其背后的矩阵运算奥秘。
一、EdgeBoard与边缘AI的挑战
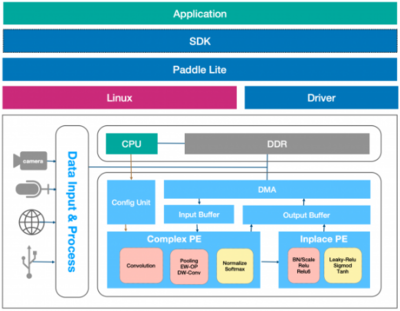
EdgeBoard的核心使命是将复杂的AI模型,尤其是CNN,从强大的云端服务器迁移至资源受限的边缘设备(如摄像头、无人机、工业网关)。这面临着三大核心挑战:计算能力有限、内存带宽紧张、功耗要求苛刻。传统的通用处理器(CPU)难以胜任,因此EdgeBoard通常采用定制化的FPGA或ASIC芯片,通过硬件级的并行优化来应对这些挑战。
二、CNN架构的核心:卷积的矩阵化
卷积神经网络之所以在视觉任务中表现卓越,卷积层功不可没。其核心操作是卷积核在输入特征图上的滑动窗口计算。在硬件实现中,尤其是为了发挥并行计算优势,将卷积运算转化为大规模的矩阵乘法(GEMM)是至关重要的优化策略。
- Im2Col(Image to Column)变换:这是最经典的优化方法。它将输入特征图的每个局部感受野(与卷积核大小对应)展开(im2col)成矩阵的一列,将多个卷积核的权重展开成矩阵的行。如此,复杂的卷积操作便转化为了两个矩阵(展开后的输入矩阵与权重矩阵)的乘法。EdgeBoard的硬件设计会深度优化这一变换过程,减少数据搬运开销。
- Winograd算法:对于较小的卷积核(如3x3),Winograd算法可以通过减少乘法次数来进一步提升计算效率。EdgeBoard的编译器或硬件逻辑可能会在特定层智能地选择使用Winograd算法来加速。
三、EdgeBoard的硬件架构如何加速矩阵运算
EdgeBoard的硬件(以FPGA方案为例)并非通用处理器,其设计紧紧围绕着高效执行CNN的矩阵/向量运算。
- 高度并行化:FPGA可以配置大量的并行计算单元(PE),每个PE负责处理矩阵乘法中的一个或一组运算。这些PE可以同时工作,极大地提升了卷积(即矩阵乘法)的吞吐量。
- 数据流架构与片上缓存:为了缓解内存带宽压力,EdgeBoard硬件采用精细的数据流设计。通过层次化的片上缓存(Buffer),将输入特征图、权重和中间结果尽可能地保留在芯片内部,实现数据的“重用以减少访存”,这是提升能效比的关键。
- 定制数据精度:EdgeBoard支持INT8等低精度量化。将FP32模型量化为INT8后,矩阵乘法的操作数位宽大幅降低,这意味着同样的硬件资源可以处理更多的并行计算,同时内存占用和带宽消耗也显著下降,非常适合边缘场景。
四、从模型到部署:编译与优化
将训练好的CNN模型部署到EdgeBoard上并非简单的移植,需要经过其专用工具链的编译与优化。这个过程可以理解为对CNN计算图的“硬件友好型重构”。
- 计算图优化:工具链会进行算子融合(如将Conv、BN、ReLU融合为一个计算单元)、层间调度优化,以减少中间数据的读写。
- 内存布局优化:根据硬件特性,将矩阵数据在内存中的排列方式(如NCHW或NHWC)调整为最优格式,以最大化数据访问的局部性和并行性。
- 指令生成:优化后的计算图被编译为可以在EdgeBoard硬件上高效执行的指令序列,精确控制每一个计算单元和数据流。
五、与展望
对EdgeBoard中CNN架构的剖析,揭示了边缘AI部署的核心逻辑:通过算法(矩阵化变换、量化)与硬件(并行PE、数据流、定制存储)的协同设计,将CNN的计算密集部分——卷积及其背后的矩阵运算——极致优化。这不仅是一个工程问题,更是算法、编译器和硬件架构的深度耦合。
随着神经网络架构的演进(如Vision Transformer的出现),EdgeBoard这类边缘计算平台也将持续进化,但其核心思想——针对核心计算模式进行软硬件一体的定制化加速——将始终是突破边缘算力瓶颈的不二法门。从矩阵运算的微观优化到系统级的部署,EdgeBoard为我们展示了AI真正走入万物互联时代的坚实技术路径。